All Publications
Conferences
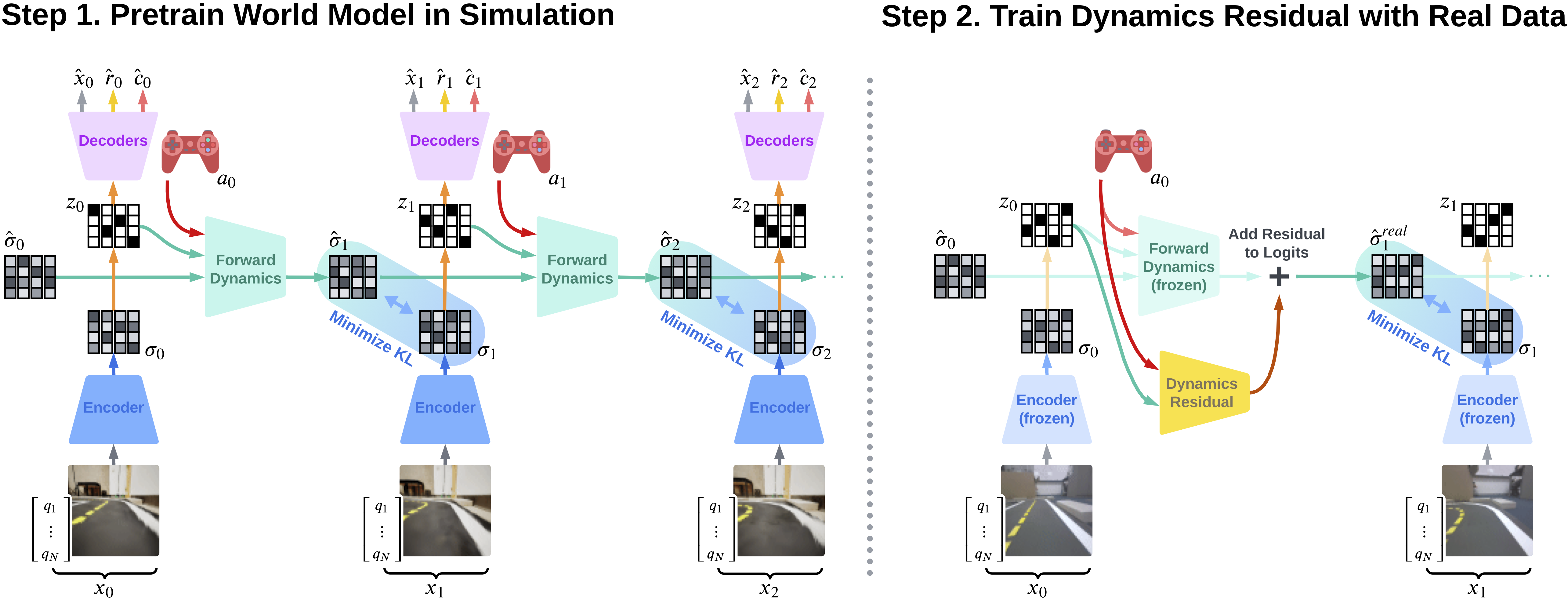
Adapting World Models with Latent-State Dynamics Residuals
JB Lanier, Kyungmin Kim, Armin Karamzade, Yifei Liu, Ankita Sinha, Kathleen He, Davide Corsi, and Roy Fox
8th Annual Learning for Dynamics and Control Conference (L4DC), 2026
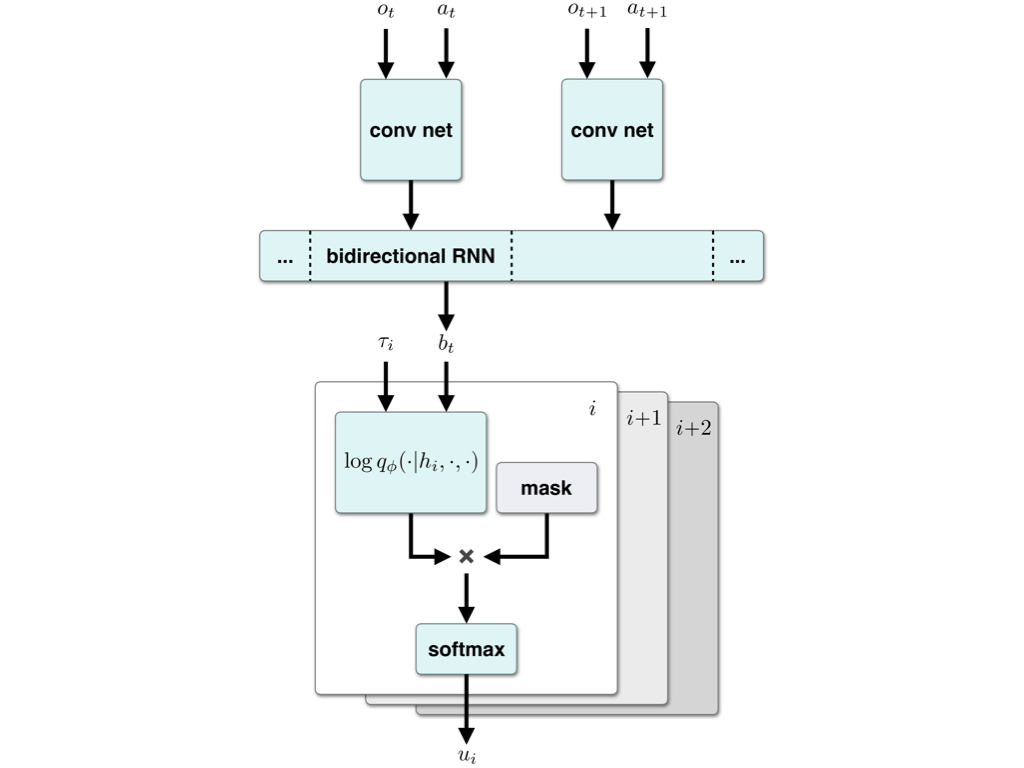
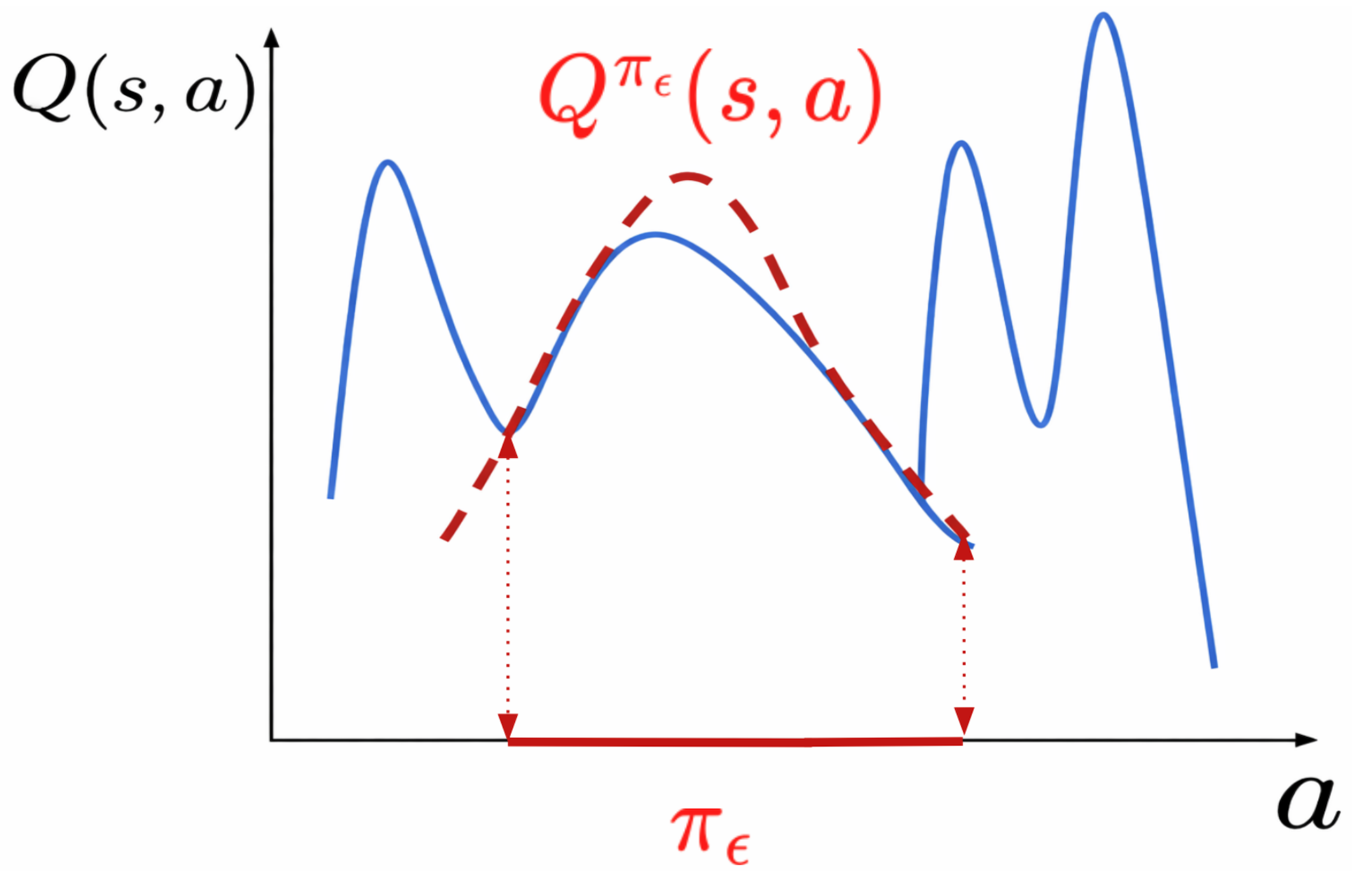
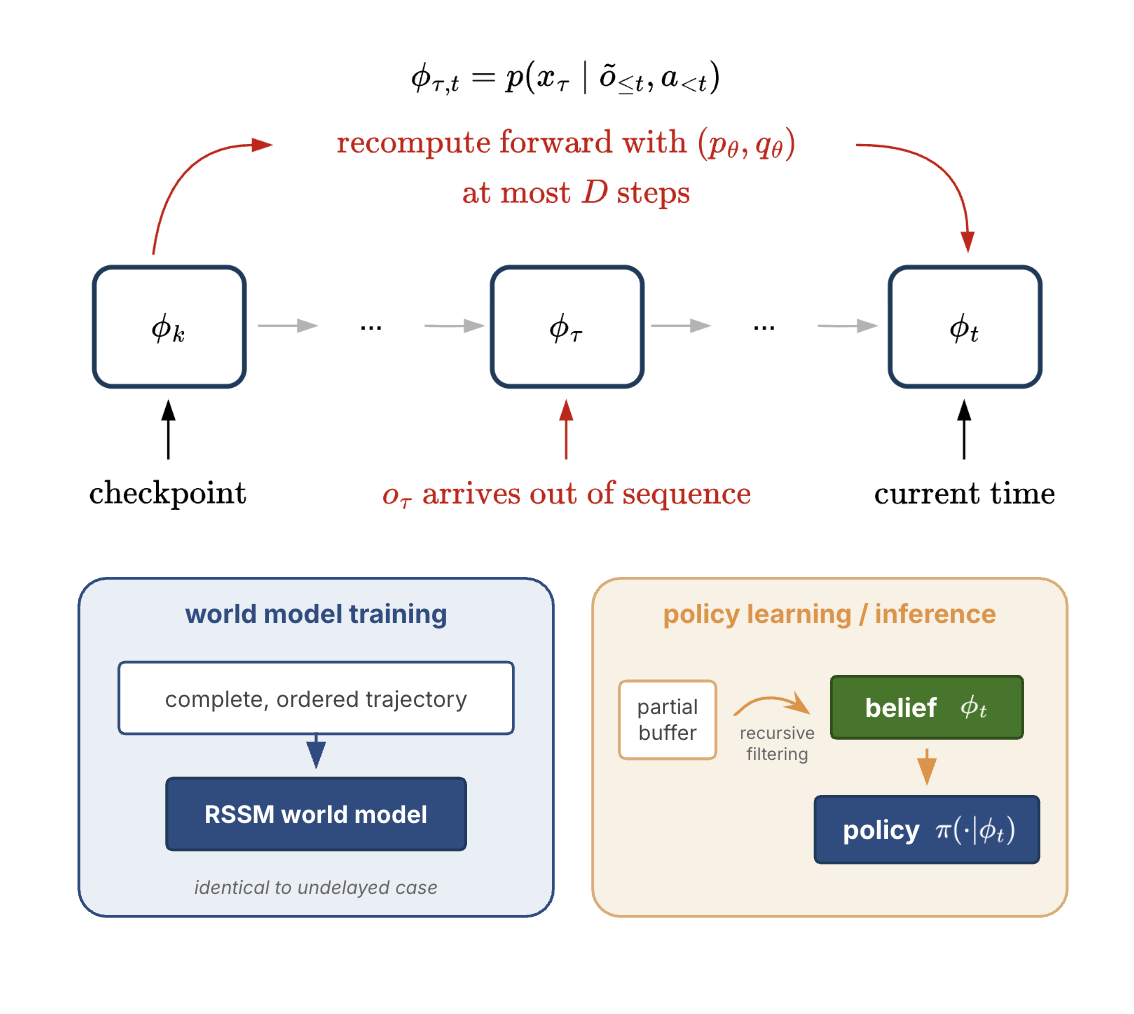
Model-Based Reinforcement Learning under Random Observation Delays
Armin Karamzade, Kyungmin Kim, JB Lanier, Davide Corsi, and Roy Fox
8th Annual Learning for Dynamics and Control Conference (L4DC), 2026
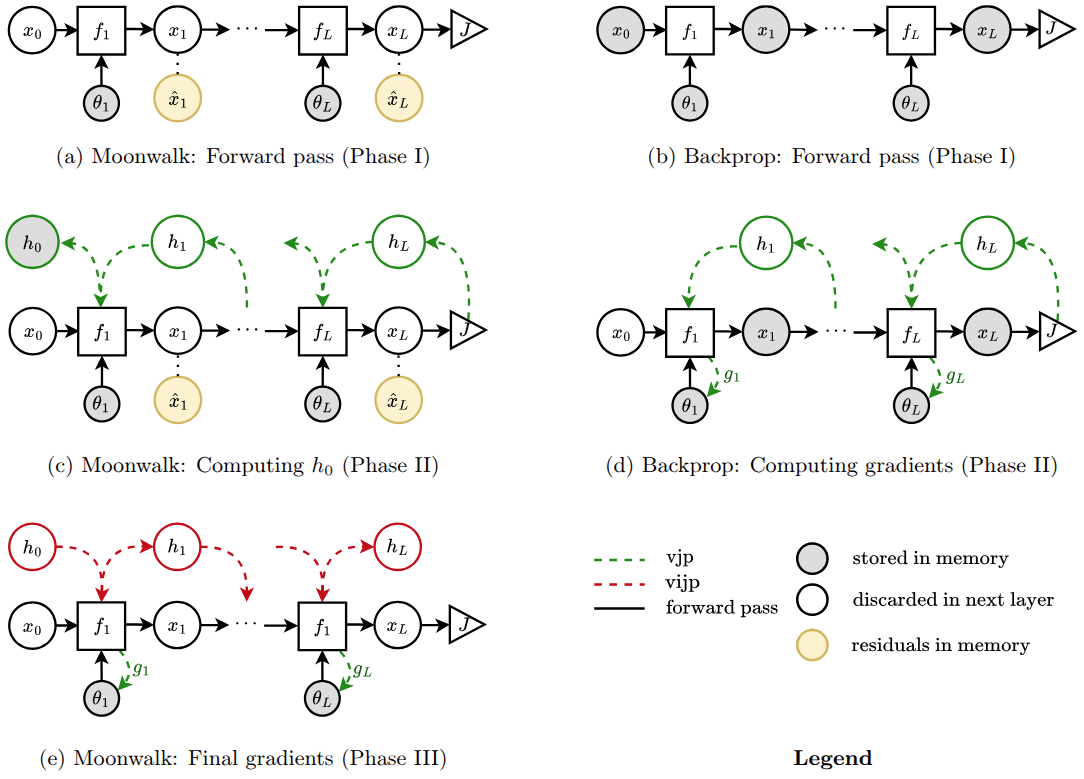
Moonwalk: Inverse-Forward Differentiation
Dmitrii Krylov, Armin Karamzade, and Roy Fox
29th Annual Conference on Artificial Intelligence and Statistics (AISTATS), 2026
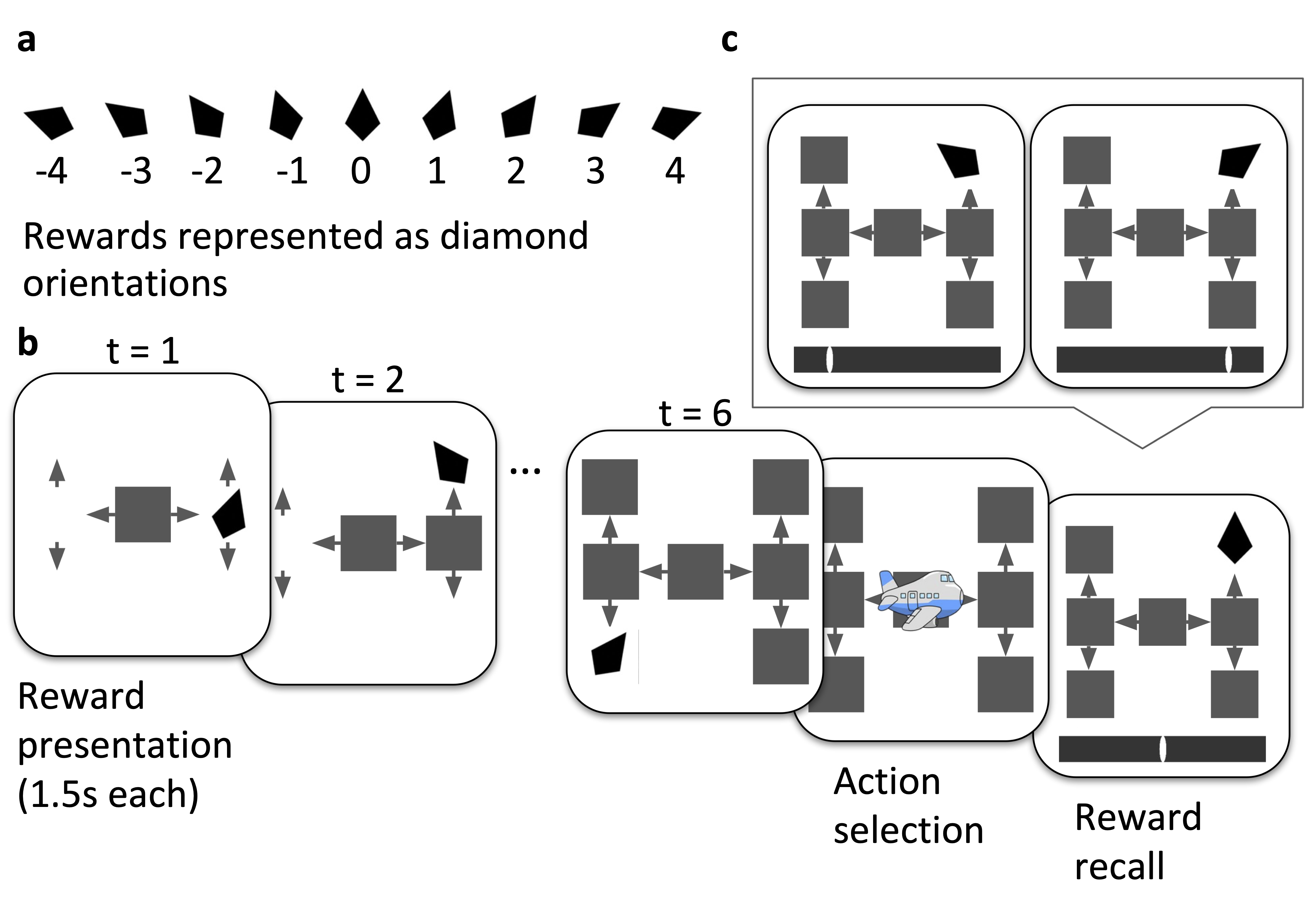
A Variational Neural Network Model of Resource-Rational Reward Encoding in Human Planning
Zhuojun Ying, Frederick Callaway, Roy Fox, Anastasia Kiyonaga, and Marcelo Mattar
47th Annual Meeting of the Cognitive Science Society (CogSci), 2025
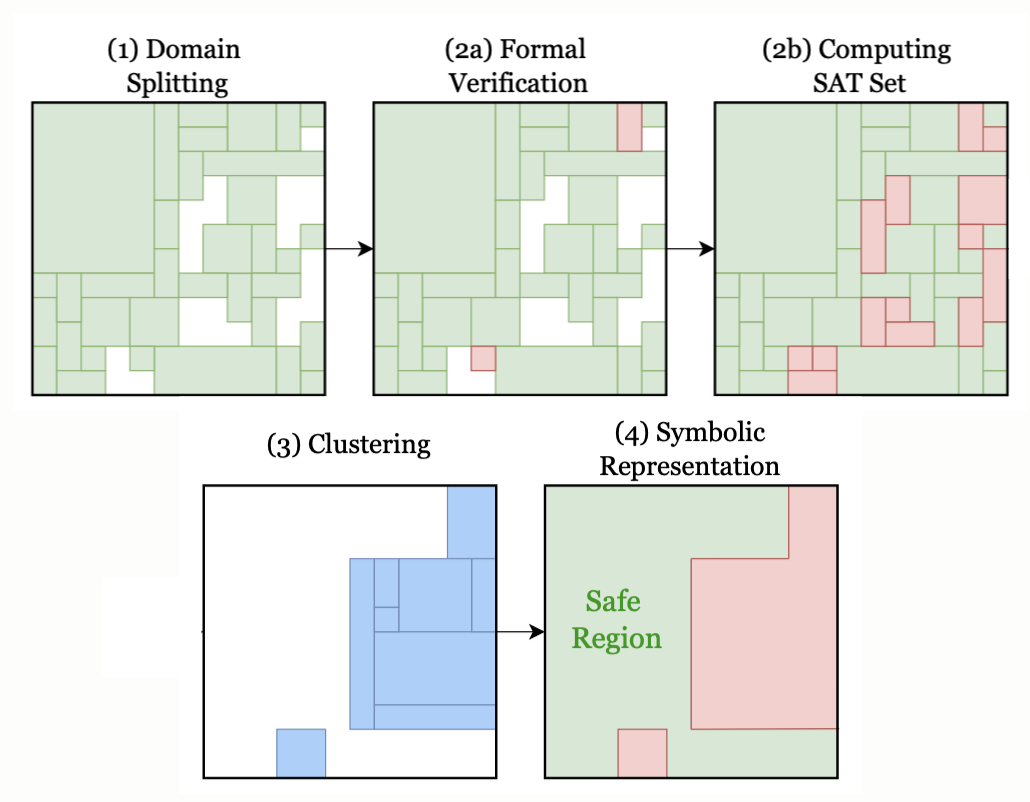
Realizable Continuous-Space Shields for Safe Reinforcement Learning
Kyungmin Kim*, Davide Corsi*, Andoni Rodríguez*, JB Lanier, Benjami Parellada, Pierre Baldi, César Sánchez, and Roy Fox
7th Annual Learning for Dynamics & Control Conference (L4DC), 2025
Verification-Guided Shielding for Deep Reinforcement Learning
Davide Corsi, Guy Amir, Andoni Rodríguez, César Sánchez, Guy Katz, and Roy Fox
1st Reinforcement Learning Conference (RLC), 2024
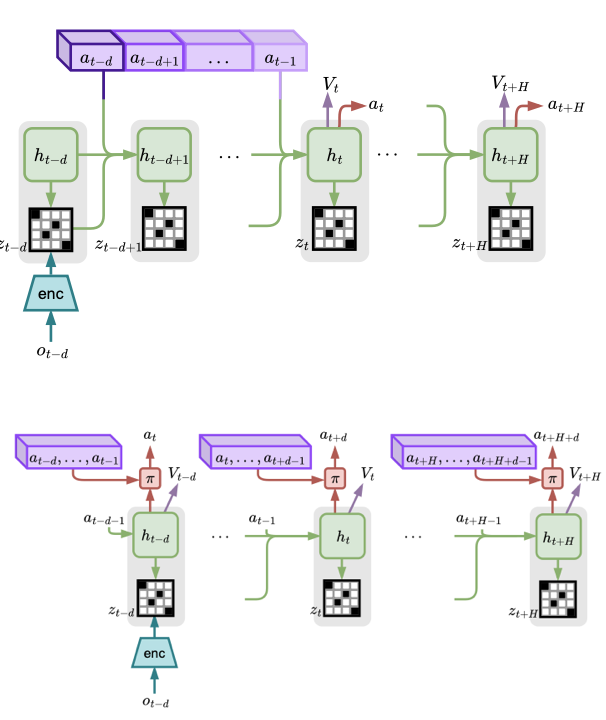
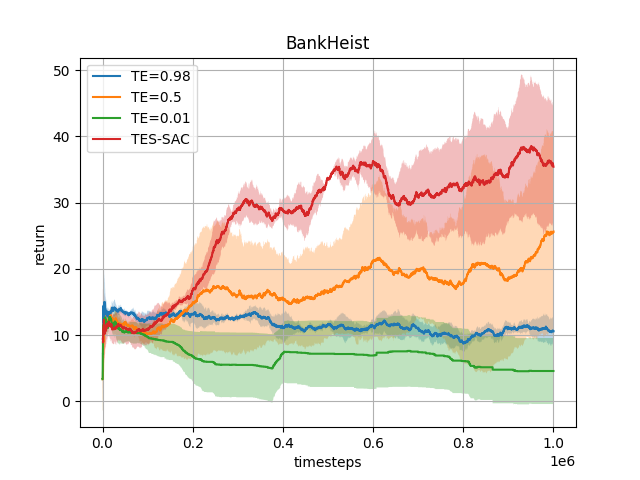
Reinforcement Learning from Delayed Observations via World Models
Armin Karamzade, Kyungmin Kim, Montek Kalsi, and Roy Fox
1st Reinforcement Learning Conference (RLC), 2024
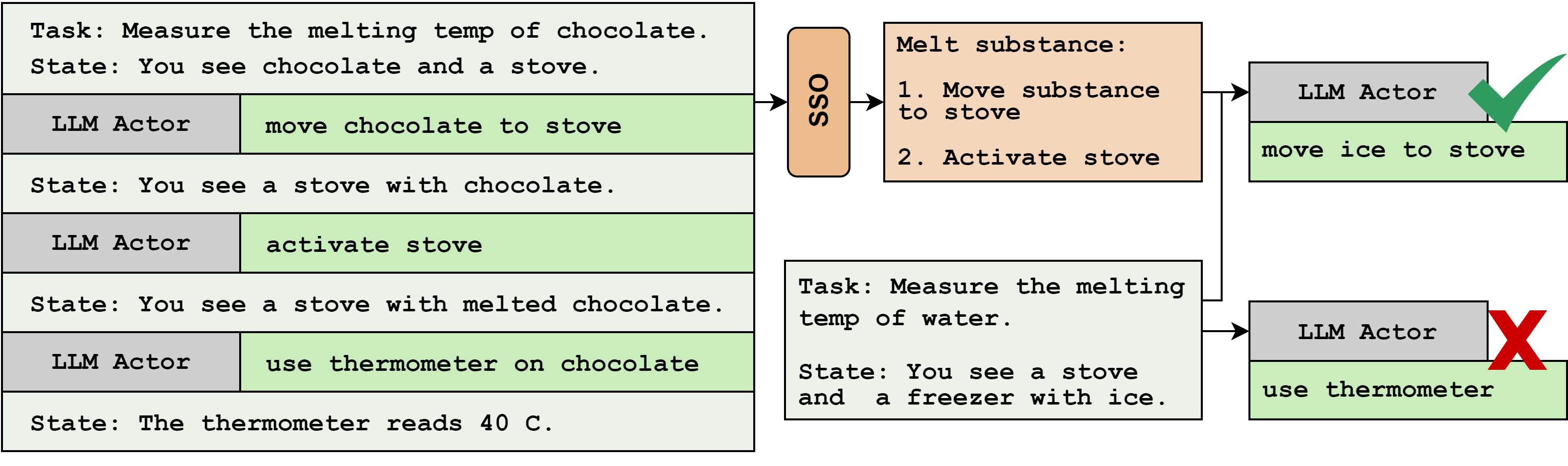
Skill Set Optimization: Reinforcing Language Model Behavior via Transferable Skills
Kolby Nottingham, Bodhisattwa Prasad Majumder, Bhavana Dalvi Mishra, Sameer Singh, Peter Clark, and Roy Fox
41st International Conference on Machine Learning (ICML), 2024
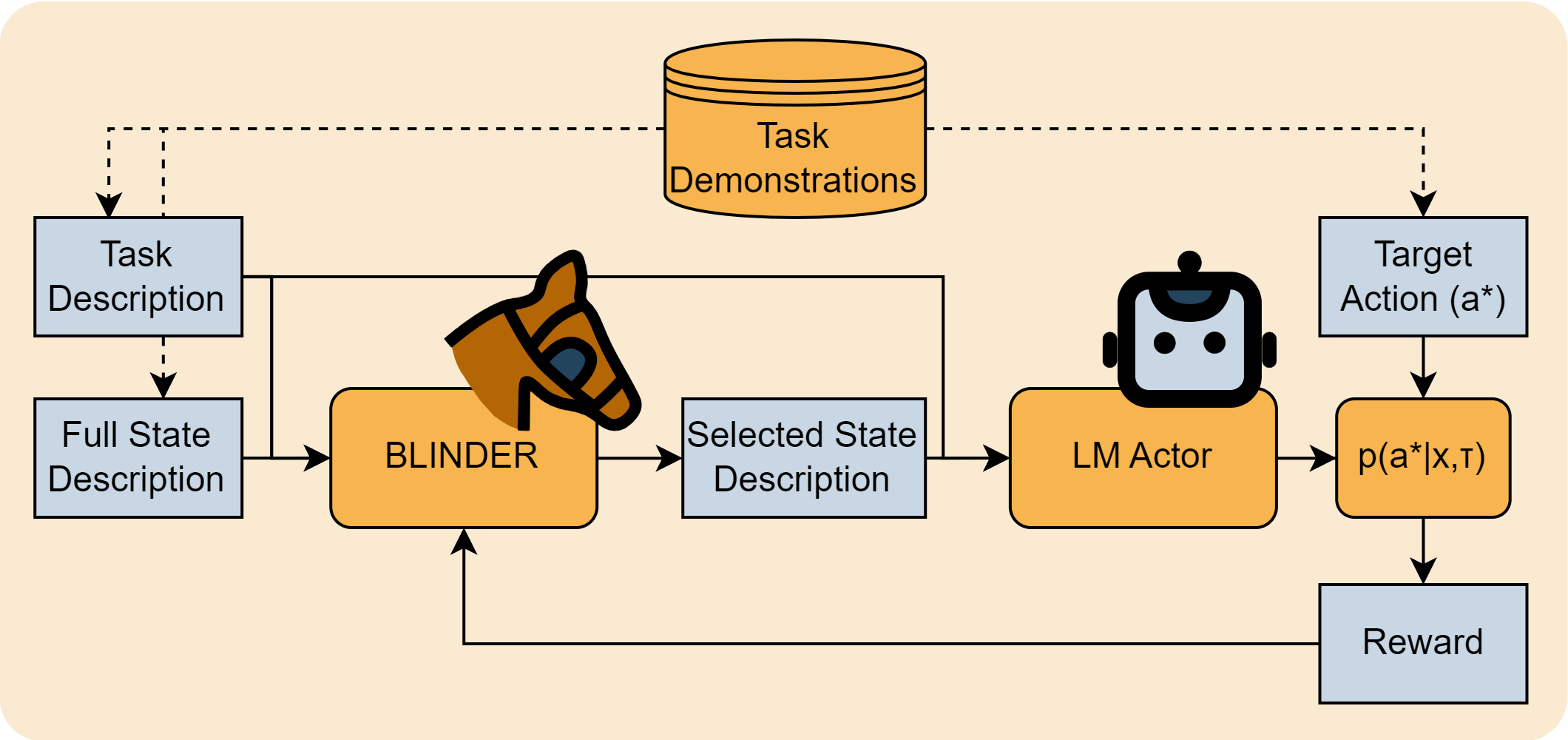
Selective Perception: Learning Concise State Descriptions for Language Model Actors
Kolby Nottingham, Yasaman Razeghi, Kyungmin Kim, JB Lanier, Pierre Baldi, Roy Fox, and Sameer Singh
2024 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), 2024
Toward Optimal Policy Population Growth in Two-Player Zero-Sum Games
Stephen McAleer, JB Lanier, Kevin Wang, Pierre Baldi, Tuomas Sandholm, and Roy Fox
12th International Conference on Learning Representations (ICLR), 2024
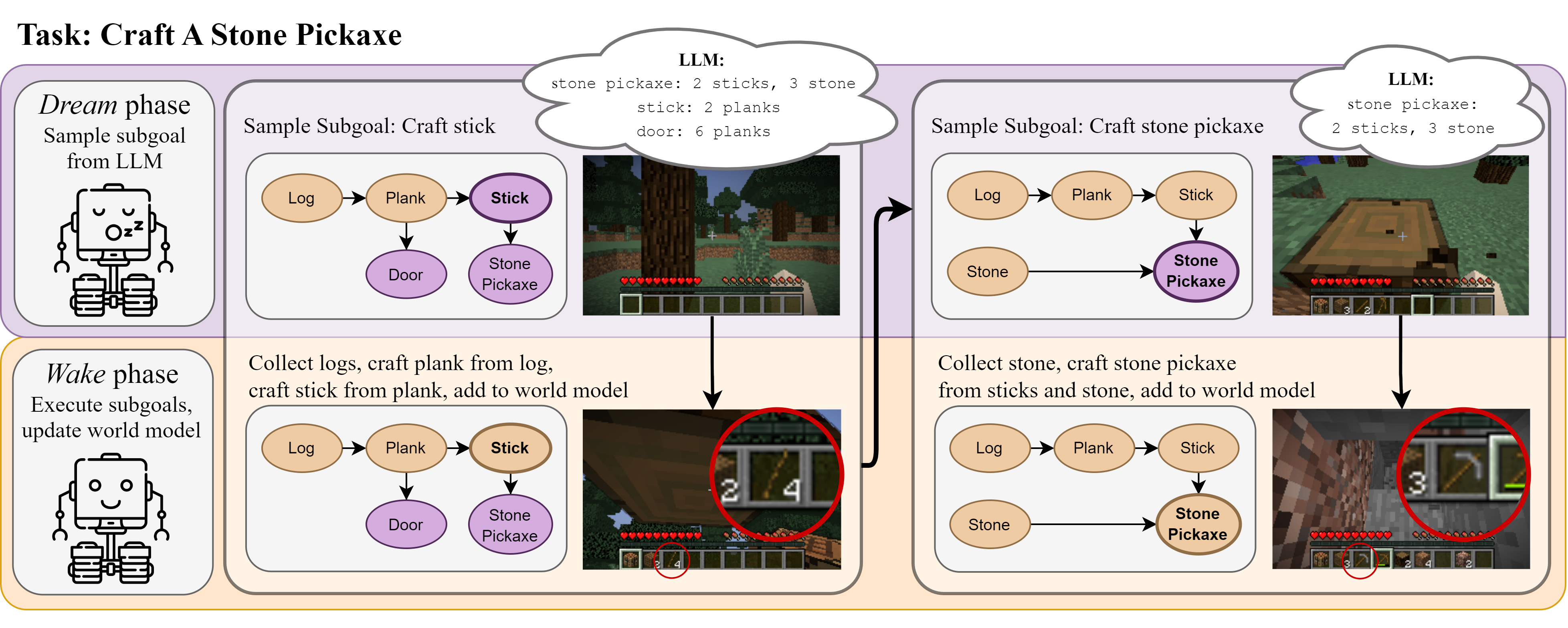
Do Embodied Agents Dream of Pixelated Sheep?: Embodied Decision Making using Language Guided World Modelling
Kolby Nottingham, Prithviraj Ammanabrolu, Alane Suhr, Yejin Choi, Hannaneh Hajishirzi, Sameer Singh, and Roy Fox
40th International Conference on Machine Learning (ICML), 2023
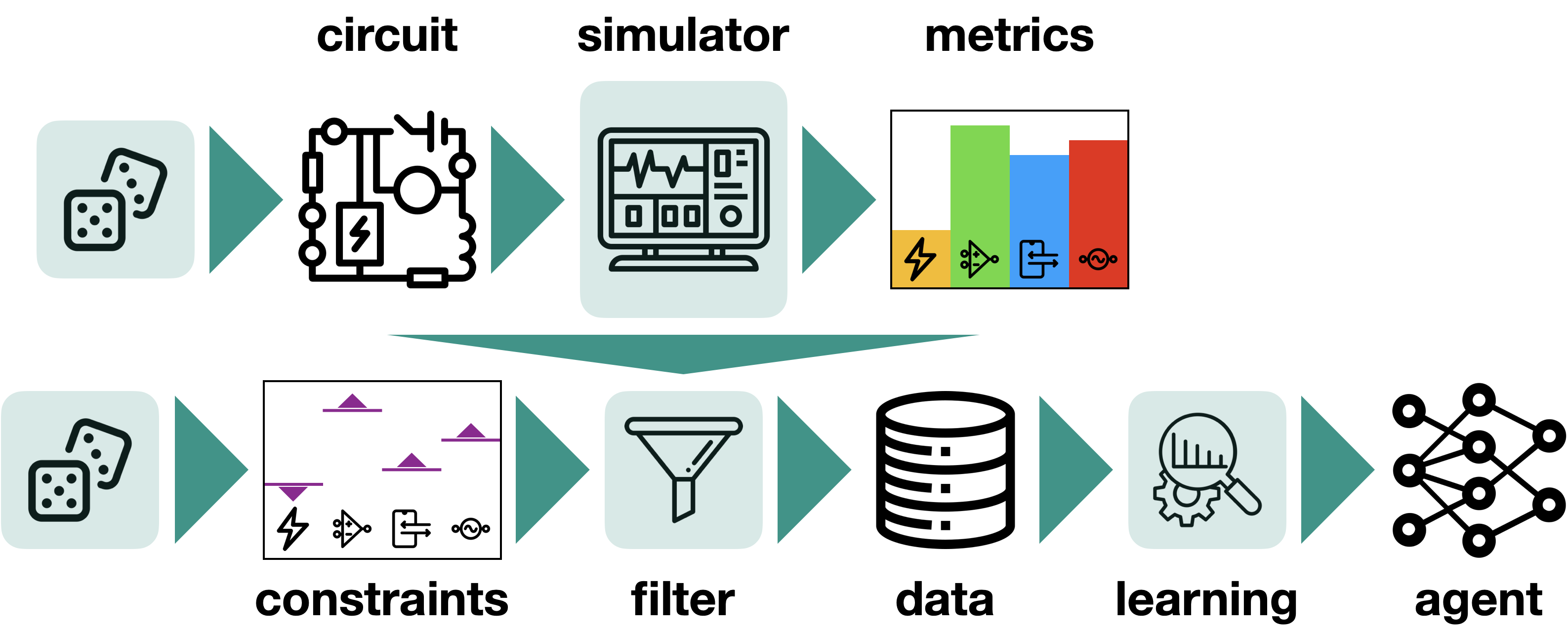
Learning to Design Analog Circuits to Meet Threshold Specifications
Dmitrii Krylov, Pooya Khajeh, Junhan Ouyang, Thomas Reeves, Tongkai Liu, Hiba Ajmal, Hamidreza Aghasi, and Roy Fox
40th International Conference on Machine Learning (ICML), 2023
Reducing Variance in Temporal-Difference Value Estimation via Ensemble of Deep Networks
Litian Liang, Yaosheng Xu, Stephen McAleer, Dailin Hu, Alexander Ihler, Pieter Abbeel, and Roy Fox
39th International Conference on Machine Learning (ICML), 2022
Independent Natural Policy Gradient Always Converges in Markov Potential Games
Roy Fox, Stephen McAleer, William Overman, and Ioannis Panageas
25th International Conference on Artificial Intelligence and Statistics (AISTATS), 2022
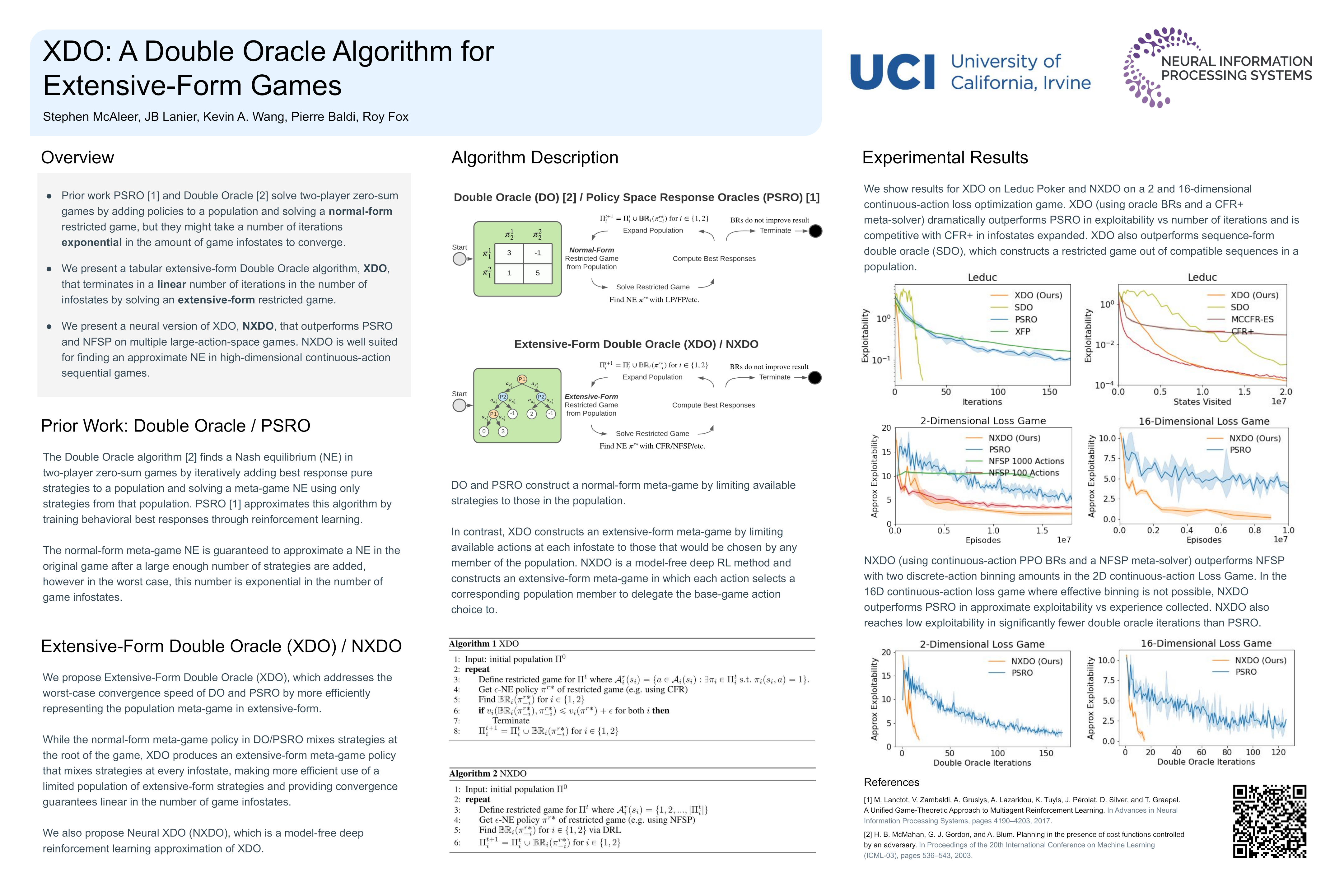
XDO: A Double Oracle Algorithm for Extensive-Form Games
Stephen McAleer, JB Lanier, Kevin Wang, Pierre Baldi, and Roy Fox
35th Conference on Neural Information Processing Systems (NeurIPS), 2021
Pipeline PSRO: A Scalable Approach for Finding Approximate Nash Equilibria in Large Games
Stephen McAleer*, JB Lanier*, Roy Fox, and Pierre Baldi
34th Conference on Neural Information Processing Systems (NeurIPS), 2020
AutoPandas: Neural-Backed Generators for Program Synthesis
Rohan Bavishi, Caroline Lemieux, Roy Fox, Koushik Sen, and Ion Stoica
10th ACM SIGPLAN Conference on Systems, Programming, Languages, and Applications: Software for Humanity (SPLASH OOPSLA), 2019
Multi-Task Hierarchical Imitation Learning for Home Automation
Roy Fox*, Ron Berenstein*, Ion Stoica, and Ken Goldberg
15th IEEE International Conference on Automation Science and Engineering (CASE), 2019
Workshops
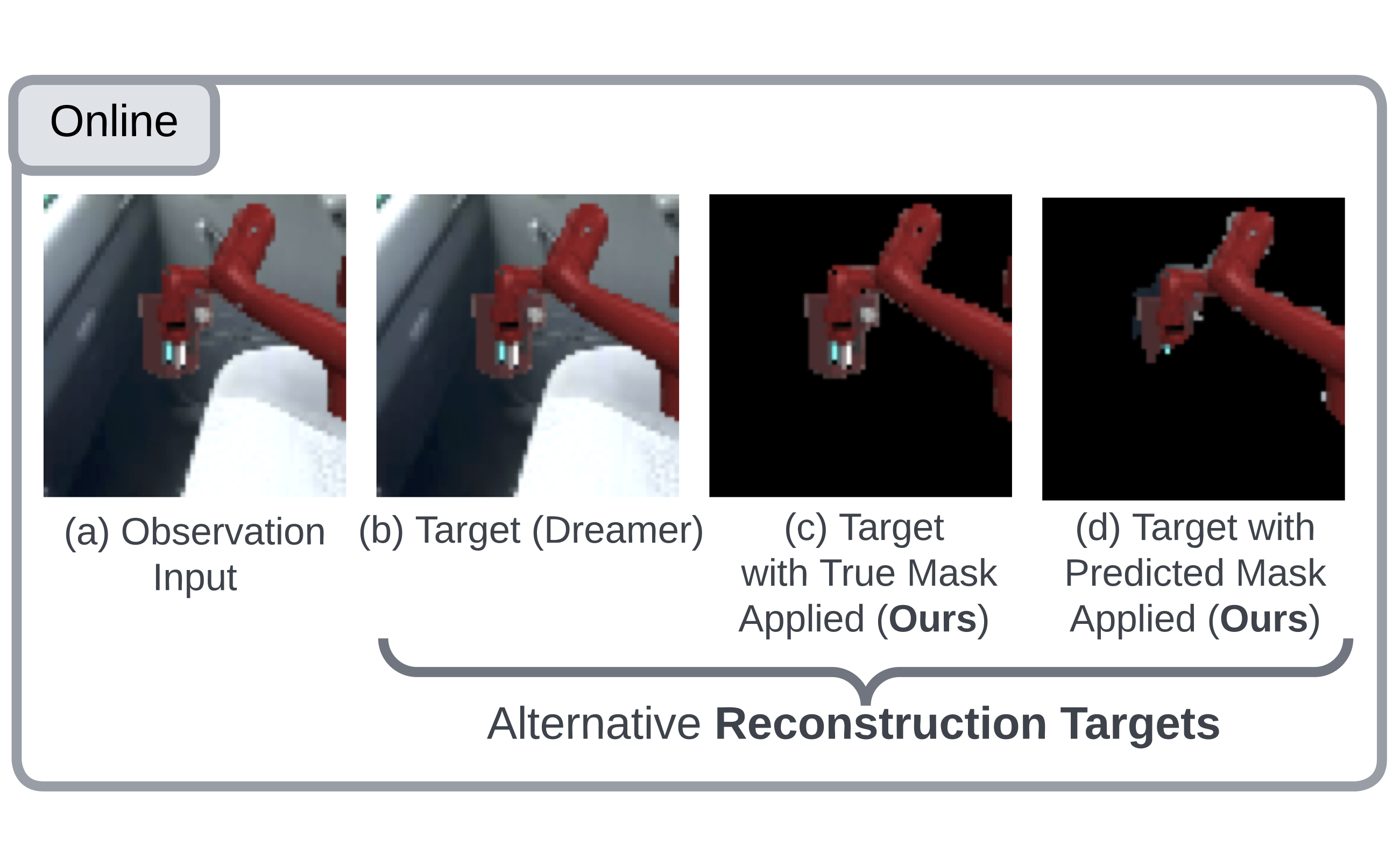
Make the Pertinent Salient: Task-Relevant Reconstruction for Visual Control with Distraction
Kyungmin Kim, Charless Fowlkes, and Roy Fox
Training Agents with Foundation Models workshop (TAFM @ RLC), 2024
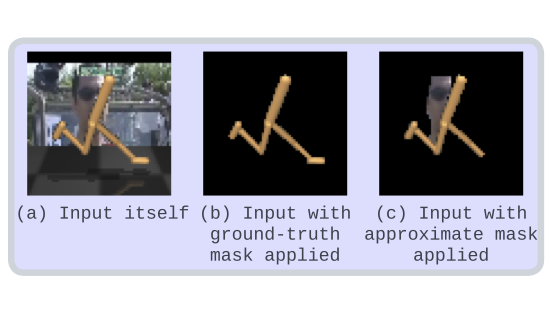
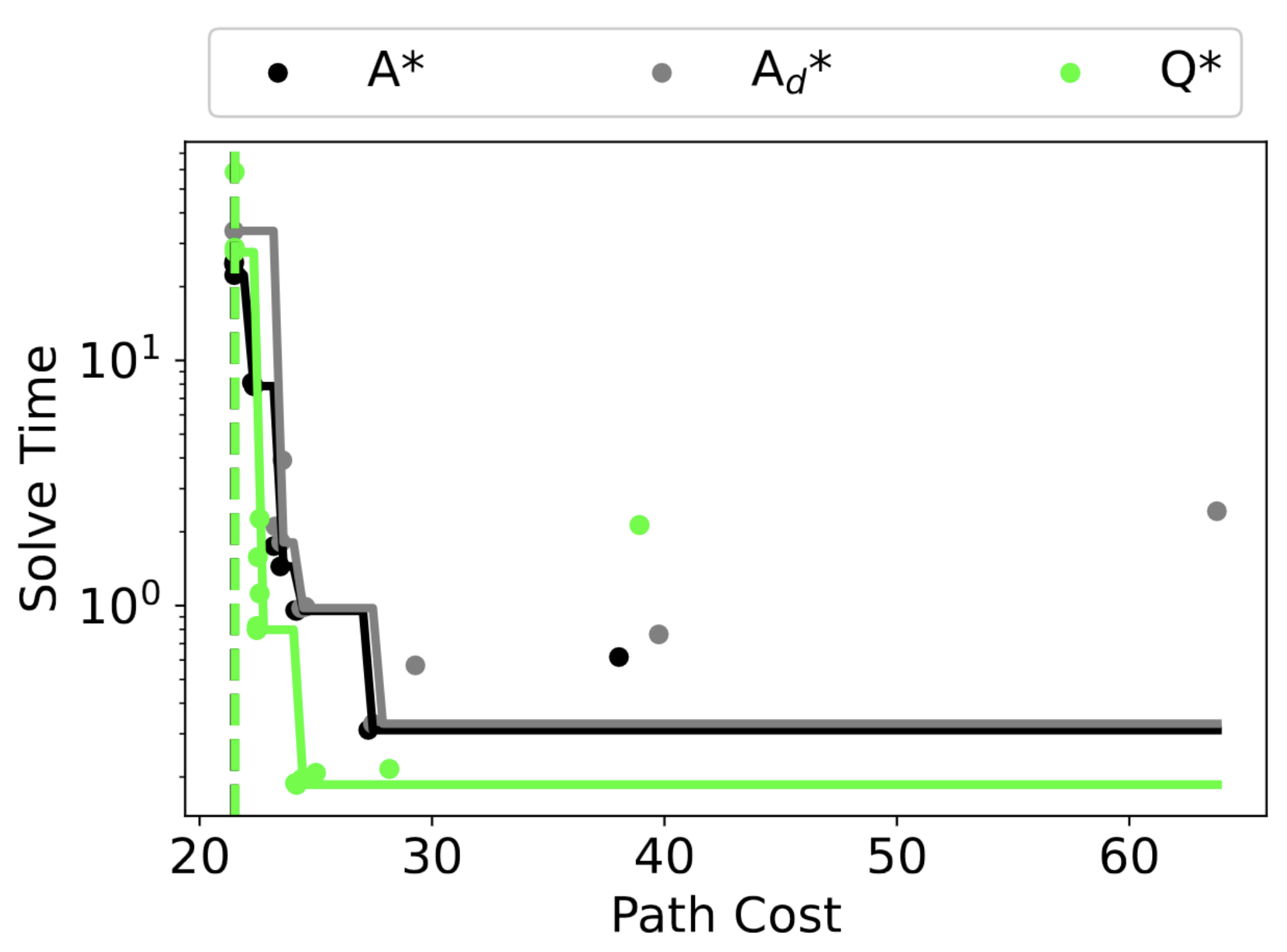
Q* Search: Heuristic Search with Deep Q-Networks
Forest Agostinelli, Shahaf Shperberg, Alexander Shmakov, Stephen McAleer, Roy Fox, and Pierre Baldi
Bridging the Gap Between AI Planning and Reinforcement Learning workshop (PRL @ ICAPS), 2024
Selective Perception: Learning Concise State Descriptions for Language Model Actors
Kolby Nottingham, Yasaman Razeghi, Kyungmin Kim, JB Lanier, Pierre Baldi, Roy Fox, and Sameer Singh
Foundation Models for Decision Making workshop (FMDM @ NeurIPS), 2023
Do Embodied Agents Dream of Pixelated Sheep?: Embodied Decision Making using Language Guided World Modelling
Kolby Nottingham, Prithviraj Ammanabrolu, Alane Suhr, Yejin Choi, Hannaneh Hajishirzi, Sameer Singh, and Roy Fox
Reincarnating Reinforcement Learning workshop (RRL @ ICLR), 2023
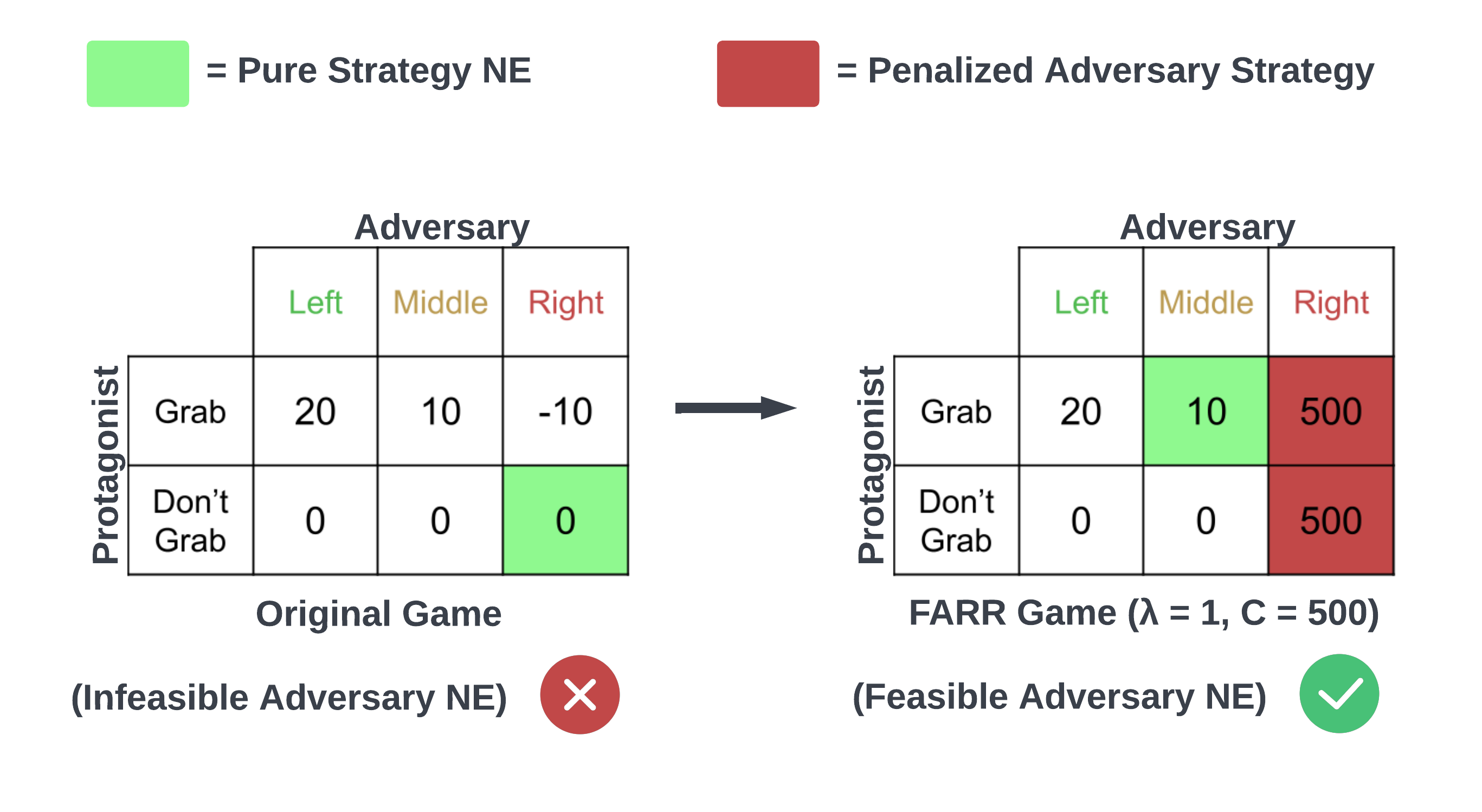
Feasible Adversarial Robust Reinforcement Learning for Underspecified Environments
JB Lanier, Stephen McAleer, Pierre Baldi, and Roy Fox
Deep Reinforcement Learning workshop (DRL @ NeurIPS), 2022
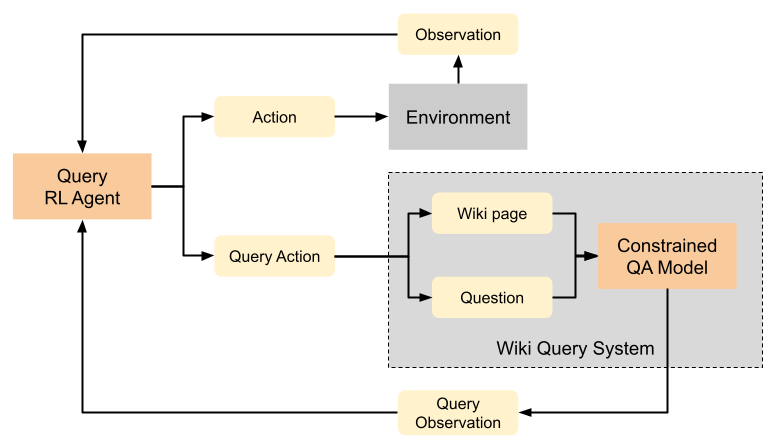
Learning to Query Internet Text for Informing Reinforcement Learning Agents
Kolby Nottingham, Alekhya Pyla, Sameer Singh, and Roy Fox
Reinforcement Learning and Decision Making (RLDM), 2022
Anytime PSRO for Two-Player Zero-Sum Games
Stephen McAleer, Kevin Wang, JB Lanier, Marc Lanctot, Pierre Baldi, Tuomas Sandholm, and Roy Fox
Reinforcement Learning in Games workshop (RLG @ AAAI), 2022
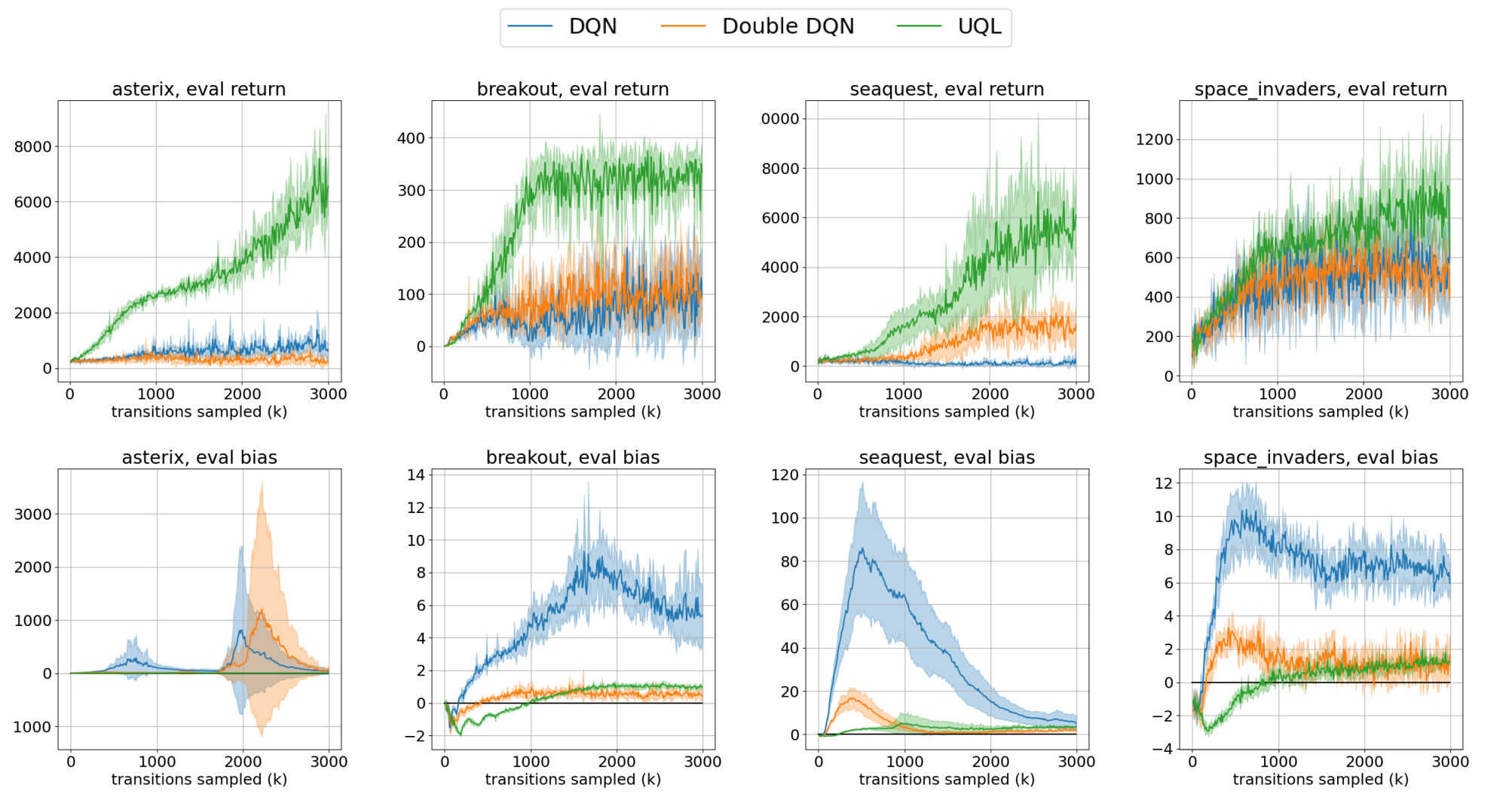
Temporal-Difference Value Estimation via Uncertainty-Guided Soft Updates
Litian Liang, Yaosheng Xu, Stephen McAleer, Dailin Hu, Alexander Ihler, Pieter Abbeel, and Roy Fox
Deep Reinforcement Learning workshop (DRL @ NeurIPS), 2021
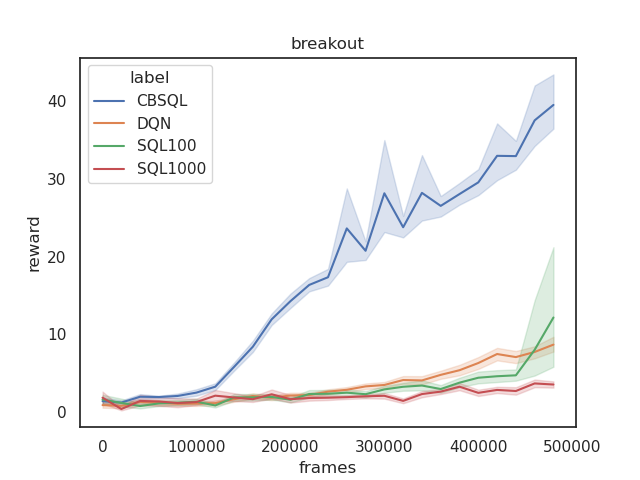
Target Entropy Annealing for Discrete Soft Actor–Critic
Yaosheng Xu, Dailin Hu, Litian Liang, Stephen McAleer, Pieter Abbeel, and Roy Fox
Deep Reinforcement Learning workshop (DRL @ NeurIPS), 2021
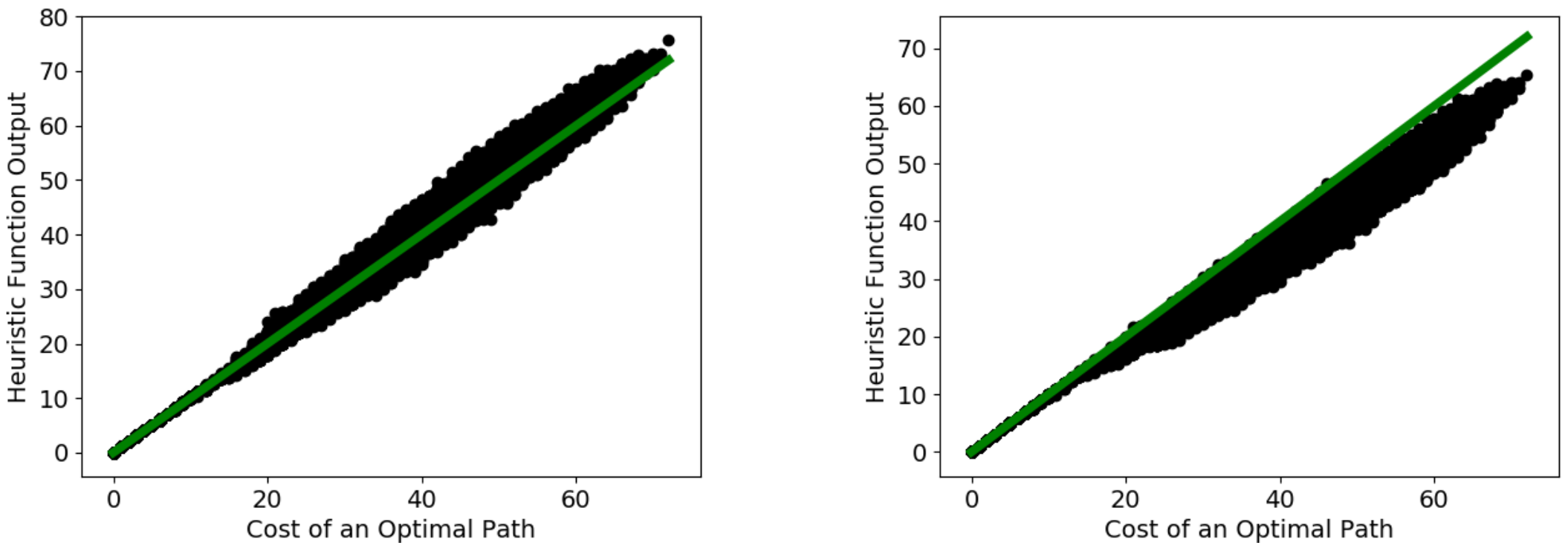
Obtaining Approximately Admissible Heuristic Functions through Deep Reinforcement Learning and A* Search
Forest Agostinelli, Stephen McAleer, Alexander Shmakov, Roy Fox, Marco Valtorta, Biplav Srivastava, and Pierre Baldi
Bridging the Gap between AI Planning and Reinforcement Learning workshop (PRL @ ICAPS), 2021
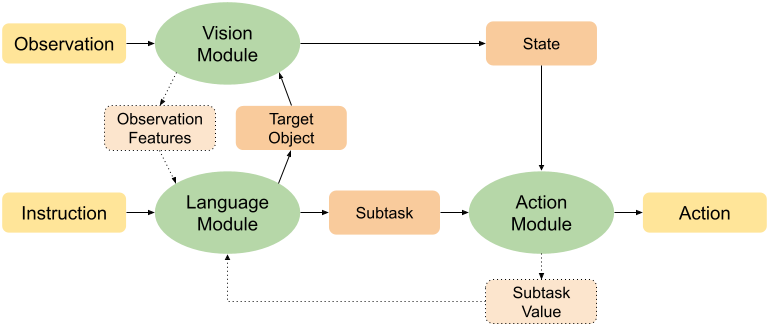
Modular Framework for Visuomotor Language Grounding
Kolby Nottingham, Litian Liang, Daeyun Shin, Charless Fowlkes, Roy Fox, and Sameer Singh
Embodied AI workshop (EmbodiedAI @ CVPR), 2021
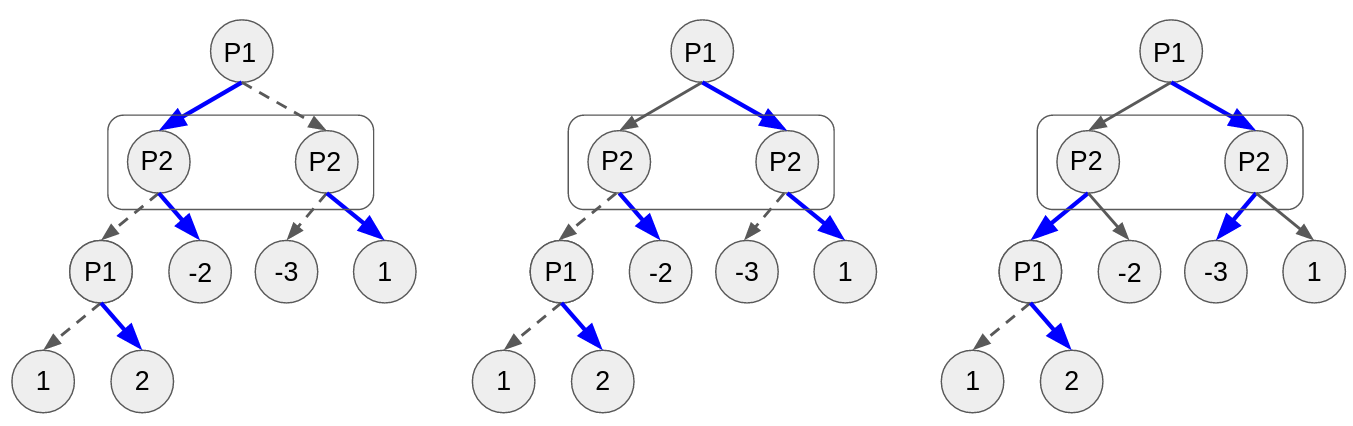
CFR-DO: A Double Oracle Algorithm for Extensive-Form Games
Stephen McAleer, JB Lanier, Pierre Baldi, and Roy Fox
Reinforcement Learning in Games workshop (RLG @ AAAI), 2021
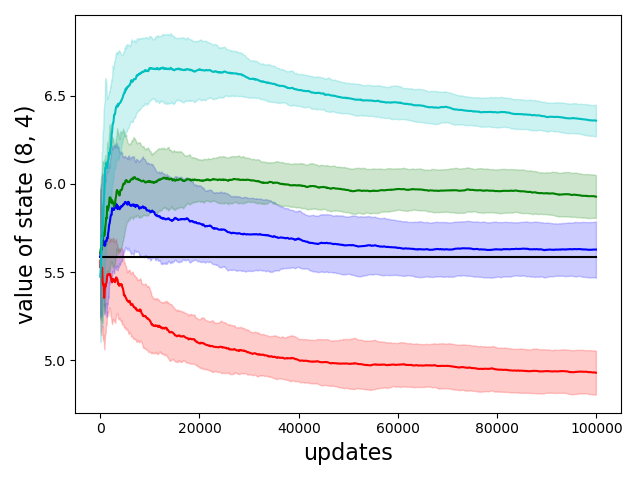
Multi-Task Learning via Task Multi-Clustering
Andy Yan, Xin Wang, Ion Stoica, Joseph Gonzalez, and Roy Fox
Adaptive & Multitask Learning workshop (AMTL @ ICML), 2019
Preprints
{kind=link}
{kind=link}
Hierarchical Variational Imitation Learning of Control Programs
Roy Fox, Richard Shin, William Paul, Yitian Zou, Dawn Song, Ken Goldberg, Pieter Abbeel, and Ion Stoica
arXiv:1912.12612, 2019