Feasible Adversarial Robust Reinforcement Learning for Underspecified Environments
JB Lanier, Stephen McAleer, Pierre Baldi, and Roy Fox
Deep Reinforcement Learning workshop (DRL @ NeurIPS), 2022
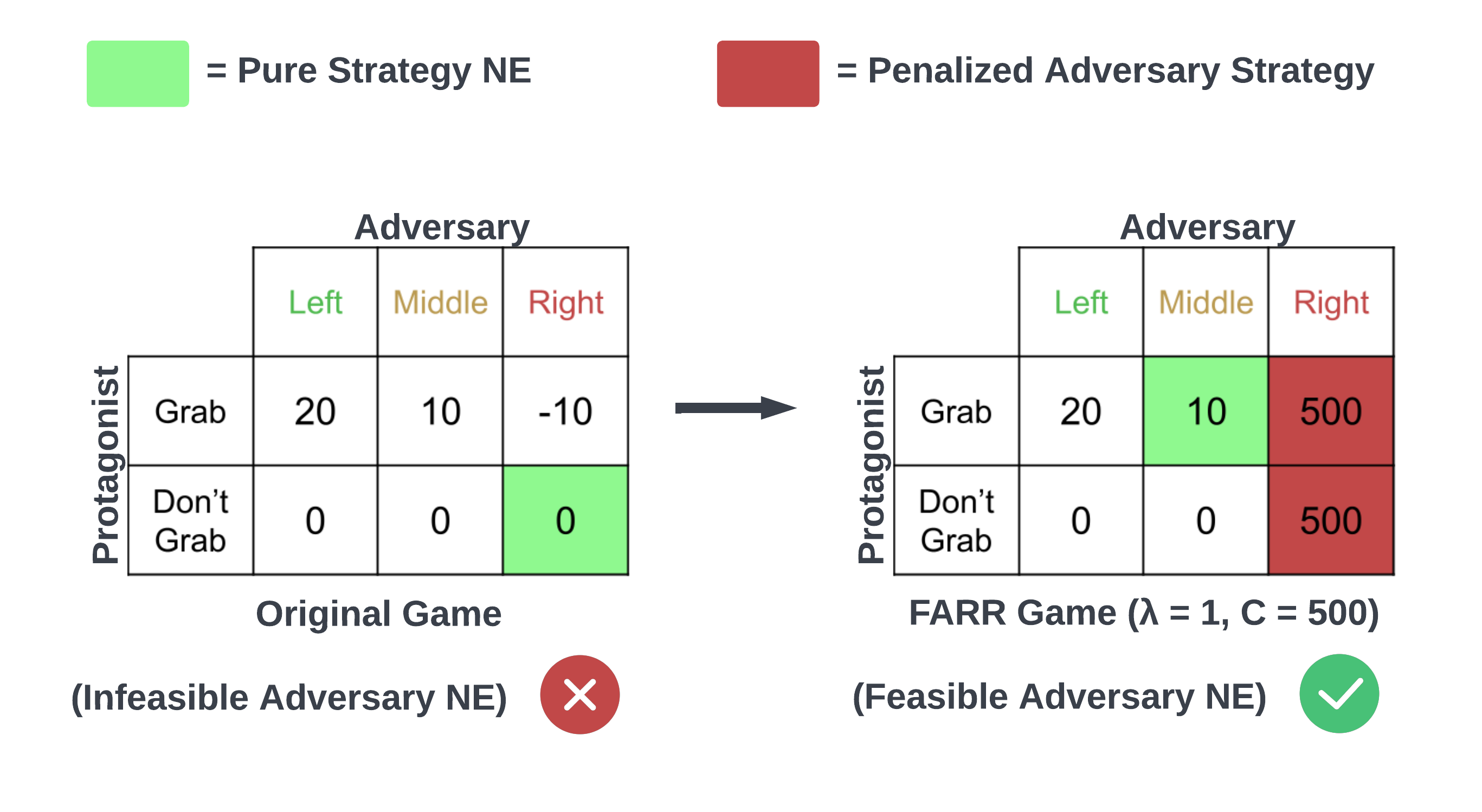
Robust reinforcement learning (RL) considers the problem of learning policies that perform well in the worst case among a set of possible environment parameter values. In real-world environments, choosing the set of possible values for robust RL can be a difficult task. When that set is specified too narrowly, the agent will be left vulnerable to reasonable parameter values unaccounted for. When specified too broadly, the agent will be too cautious. In this paper, we propose Feasible Adversarial Robust RL (FARR), a novel problem formulation and objective for automatically determining the set of environment parameter values over which to be robust. FARR implicitly defines the set of feasible parameter values as those on which an agent could achieve a benchmark reward given enough training resources. By formulating this problem as a two-player zero-sum game, optimizing the FARR objective jointly produces an adversarial distribution over parameter values with feasible support and a policy robust over this feasible parameter set. We demonstrate that approximate Nash equilibria for this objective can be found using a variation of the PSRO algorithm. Furthermore, we show that an optimal agent trained with FARR is more robust to feasible adversarial parameter selection than with existing minimax, domain-randomization, and regret objectives in a parameterized gridworld and three MuJoCo control environments.