Anytime PSRO for Two-Player Zero-Sum Games
Stephen McAleer, Kevin Wang, JB Lanier, Marc Lanctot, Pierre Baldi, Tuomas Sandholm, and Roy Fox
Reinforcement Learning in Games workshop (RLG @ AAAI), 2022
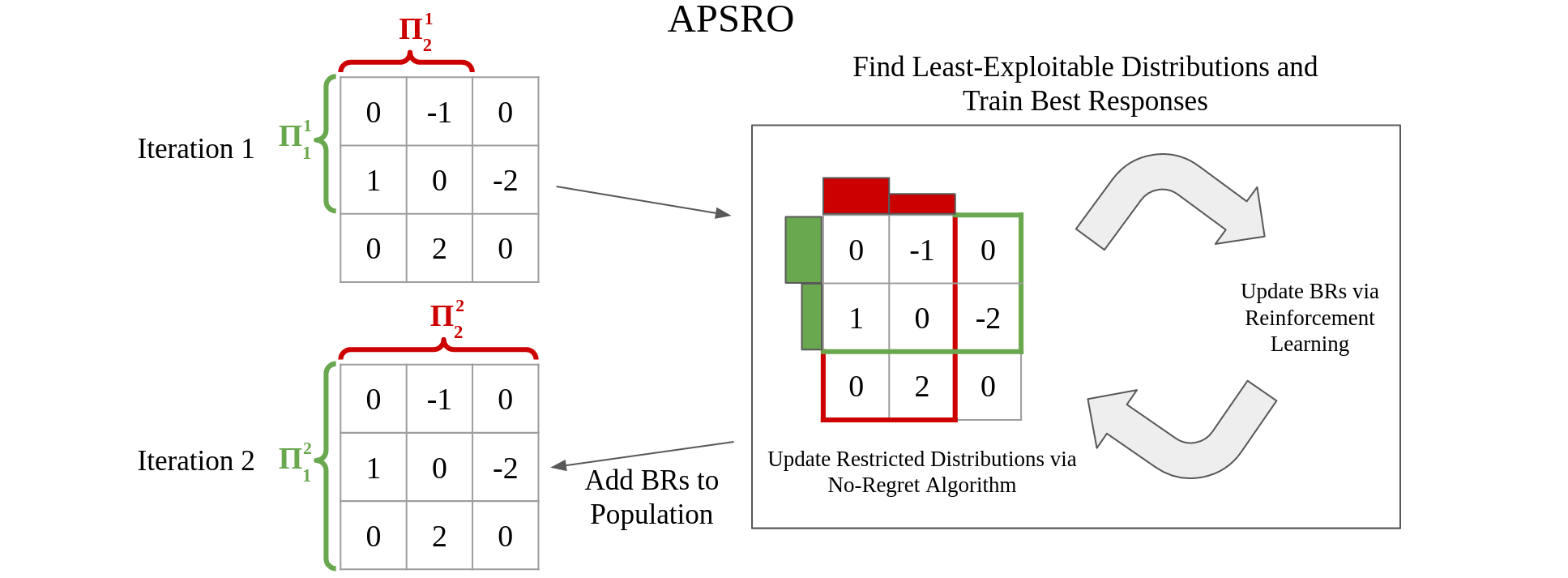
Policy space response oracles (PSRO) is a multi-agent reinforcement learning algorithm that has achieved state-of-the-art performance in very large two-player zero-sum games. PSRO is based on the tabular double oracle (DO) method, an algorithm that is guaranteed to converge to a Nash equilibrium, but may increase exploitability from one iteration to the next. We propose anytime double oracle (ADO), a tabular double oracle algorithm for 2-player zero-sum games that is guaranteed to converge to a Nash equilibrium while decreasing exploitability from one iteration to the next. Unlike DO, in which the restricted distribution is based on the restricted game formed by each player’s strategy sets, ADO finds the restricted distribution for each player that minimizes its exploitability against any policy in the full, unrestricted game. We also propose a method of finding this restricted distribution via a no-regret algorithm updated against best responses, called RM-BR DO. Finally, we propose anytime PSRO (APSRO), a version of ADO that calculates best responses via reinforcement learning. In experiments on Leduc poker and random normal form games, we show that our methods achieve far lower exploitability than DO and PSRO and decrease exploitability monotonically.