Toward Provably Unbiased Temporal-Difference Value Estimation
Roy Fox
Optimization Foundations for Reinforcement Learning workshop (OPTRL @ NeurIPS), 2019
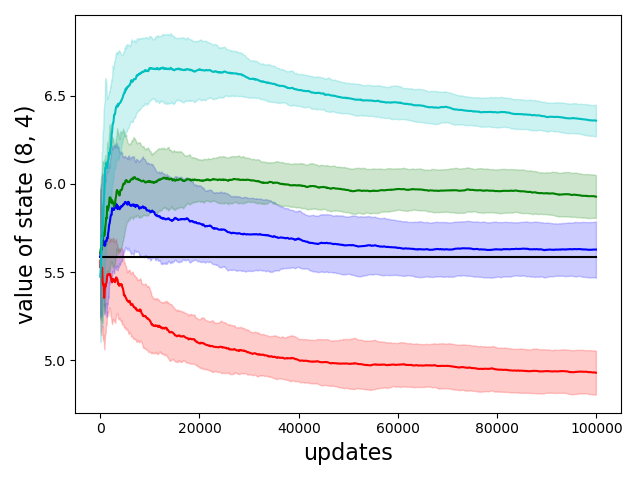
Temporal-difference learning algorithms, such as Q-learning, maintain and iteratively improve an estimate of the value that an agent can expect to gain in interaction with its environment. Unfortunately, the value updates in Q-learning induce positive bias that causes it to overestimate this value. Several algorithms, such as Soft Q-learning, regularize the value updates to reduce this bias, but none provide a principled schedule of their regularizers such that early in the learning process updates are more agnostic, but then increasingly trust the value estimates more as they become more certain during learning. In this paper, we present a closed-form expression for the regularization coefficient that completely eliminates bias in entropy-regularized value updates, and illustrate this theoretical analysis using a proof-of-concept algorithm that approximates the conditions for unbiased value estimation.