Selective Perception: Learning Concise State Descriptions for Language Model Actors
Kolby Nottingham, Yasaman Razeghi, Kyungmin Kim, JB Lanier, Pierre Baldi, Roy Fox, and Sameer Singh
Foundation Models for Decision Making workshop (FMDM @ NeurIPS), 2023
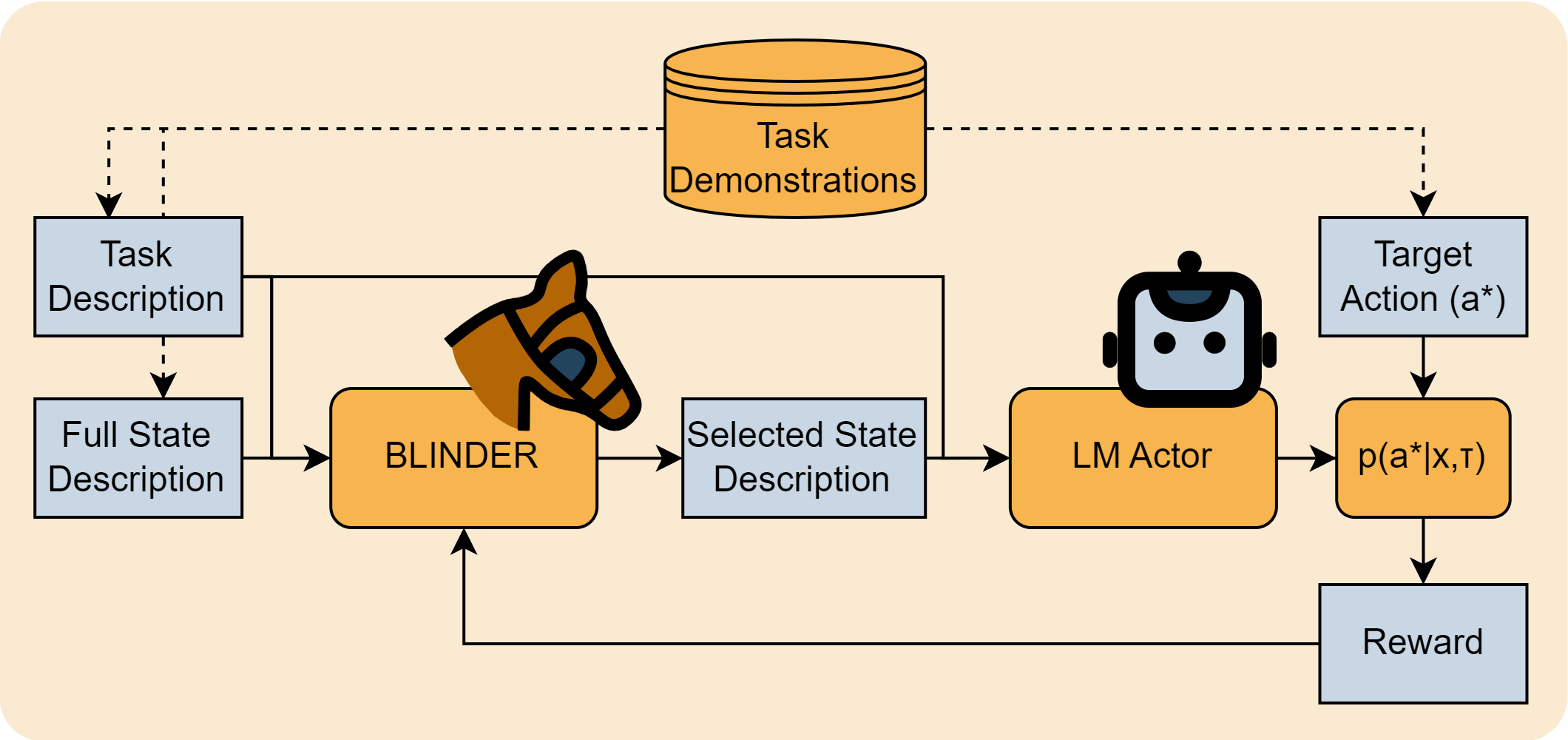
It is increasingly common for large language models (LLMs) to be applied as actors in sequential decision making problems in embodied domains such as robotics and games, due to their general world knowledge and planning abilities. However, LLMs are not natively trained for embodied decision making problems, and expressing complex state spaces in text is non-trivial. Exhaustively describing high-dimensional states leads to prohibitive inference costs and impaired task performance due to distracting or irrelevant information. Previous LLM actors avoid the issue by relying on hand-engineered, task-specific protocols to determine which features to communicate about a state and which to leave out. In this work, we propose BLINDER (Brief Language INputs for DEcision-making Responses), a method for learning to select concise and helpful sets of state features for LLM actors. BLINDER learns a value function for task-conditioned state descriptions that approximates the likelihood that a state description will result in optimal actions. We evaluate BLINDER on the challenging video game NetHack and a real-world robotic manipulation task. We find that we are able to reduce the length of state descriptions by 87% and 99% on NetHack and robotic manipulation tasks respectively. BLINDER also improves task success rates by 158% and 54% on those same tasks and generalizes to LLM actors of various size and quality.